 Hakkındaki Her Şey")
Büyük Dil Modelleri (Large Language Models - LLM), son yıllarda yapay zeka ve doğal dil işleme (NLP) alanlarında önemli ilerlemelere imza attı. Bu modeller, geniş veri kümeleri üzerinde eğitilerek insan benzeri metinler üretebilir, soruları yanıtlayabilir ve çeşitli dil görevlerini yerine getirebilir.
Büyük Dil Modelleri Nedir?
Büyük Dil Modelleri, geniş veri kümeleri üzerinde eğitilen ve dil ile ilgili çeşitli görevleri yerine getirebilen derin öğrenme modelleridir. Bu modeller, genellikle milyarlarca parametreye sahip olup, metin oluşturma, çeviri, metin sınıflandırma ve soru-cevap gibi görevlerde kullanılır. En bilinen örneklerden biri, OpenAI'nin ChatGPT modelidir, bu model 175 milyardan fazla parametre ile eğitilmiştir.
LLM'lerin Çalışma Prensibi
1. Veri Toplama ve Hazırlık: LLM'lerin eğitimi için devasa boyutlarda metin verisi kullanılır. Bu veriler, kitaplar, makaleler, web siteleri ve hatta sosyal medya paylaşımları gibi çeşitli kaynaklardan toplanır. Verilerin temizlenmesi, düzenlenmesi ve modele uygun hale getirilmesi de bu aşamada gerçekleşir.
2. Model Mimarisi: LLM'ler, genellikle Transformer adı verilen bir derin öğrenme mimarisi üzerine inşa edilir. Transformer, metindeki kelimeler arasındaki ilişkileri ve bağlamı daha iyi anlamak için "dikkat mekanizması" kullanır. Bu, modelin sadece kelimeleri değil, cümlelerin ve paragrafların anlamını da anlamasına yardımcı olur.
3. Eğitim Süreci: LLM'ler, toplanan metin verileri üzerinde "denetimsiz öğrenme" adı verilen bir yöntemle eğitilir. Bu yöntemde, model herhangi bir etiket veya doğru cevap olmadan, sadece metinleri okuyarak dilin yapısını, kelimelerin anlamlarını ve birbirleriyle olan ilişkilerini öğrenir. Eğitim süreci, genellikle milyarlarca kelime ve cümle üzerinde tekrarlanır ve bu sayede model, dilin karmaşık yapısını ve nüanslarını kavrar.
4. Tahmin ve Üretim: Eğitim tamamlandıktan sonra LLM, bir metin girdisi verildiğinde, bir sonraki kelimeyi veya cümleyi tahmin etmeye çalışır. Bu tahmin, modelin eğitim sırasında öğrendiği dil bilgisi ve kalıplara dayanır. Bu şekilde, LLM'ler metinleri özetleyebilir, soruları cevaplayabilir, çeviri yapabilir ve hatta yaratıcı içerikler üretebilir.
5. İnce Ayar (Fine-Tuning): LLM'ler, belirli bir göreve (örneğin, tıbbi metin çevirisi veya hukuki belge analizi) odaklanmak için daha küçük ve özel bir veri kümesi üzerinde "ince ayar" yapılabilir. Bu, modelin performansını belirli bir alanda daha da iyileştirmeye yardımcı olur.
LLM'lerin çalışma prensibi, karmaşık olsa da temel olarak bu adımlardan oluşur. Genel olarak LLM dil modelleri, büyük miktarda veriyi işleyerek ve dilin yapısını öğrenerek, insan dilini anlama ve üretme konusunda inanılmaz etkileyici sonuçlar elde etmeye başladı.
LLM Büyük Dil Modellerinin Tarihi ve Gelişimi
1. İlk Adımlar ve RNN Modelleri
LLM'lerin temelleri, 1990'ların sonunda ve 2000'lerin başında geliştirilen Recurrent Neural Networks (RNN) ve Long Short-Term Memory (LSTM) modelleriyle atıldı. Bu modeller, sekans verilerini işleyebilme yetenekleriyle dil modellemede önemli bir adım oluşturdu.
2. Transformer Modelinin Tanıtımı (2017)
2017 yılında, Google tarafından yayınlanan "Attention is All You Need" makalesi ile Transformer modeli tanıtıldı. Bu model, dikkat mekanizmasını kullanarak dil işleme görevlerinde RNN ve LSTM'lere göre daha etkili ve verimli çözümler sundu. Transformer, paralel işlem yapabilme yeteneği ile büyük veri kümelerinde eğitimi hızlandırdı ve daha büyük modellerin geliştirilmesine olanak tanıdı.
3. GPT Serisi ve Gelişimi
GPT (2018): OpenAI, ilk GPT modelini tanıttı. Bu model, Transformer mimarisine dayanıyordu ve metin üretiminde başarılı sonuçlar verdi.
GPT-2 (2019): Bir önceki modelin üzerine inşa edilen GPT-2, 1.5 milyar parametre ile çok daha büyük ve yetenekliydi. Bu model, metin tamamlama, çeviri ve özetleme gibi görevlerde üstün performans sergiledi.
GPT-3 (2020): GPT-3, 175 milyar parametre ile o zamana kadar geliştirilen en büyük dil modeli oldu. Çok çeşitli dil görevlerinde insan benzeri performans sergileyebiliyordu.
GPT-4 (2023): OpenAI, 2023 yılında GPT-4 modelini tanıttı. Bu model, GPT-3'ün yeteneklerini daha da ileriye taşıdı ve daha büyük bir parametre setine sahip oldu. GPT-4, dil işleme görevlerinde daha yüksek doğruluk ve tutarlılık sağladı. Ayrıca, daha az önyargılı sonuçlar üretme ve daha karmaşık metinleri anlama yeteneği geliştirildi. GPT-4, sağlık, hukuk, eğitim ve yaratıcı endüstriler gibi çeşitli alanlarda geniş bir bilgi kapasitesine sahip.
GPT serisi, her yeni sürümde önemli ilerlemeler kaydederek dil modelleme alanında çıtayı yükseltti. Bu modeller, metin üretiminden çeviriye, yaratıcı yazılardan diyalog sistemlerine kadar birçok alanda kullanılarak doğal dil işleme görevlerinde devrim yarattı ve yaratmaya da devam ediyor.
4. Diğer Büyük Dil Modelleri
BERT (2018): BERT (Bidirectional Encoder Representations from Transformers), Google tarafından 2018'de geliştirilen ve halen aktif olarak kullanılan açık kaynaklı bir dil modelidir. Metin verilerini çift yönlü olarak işleyerek kelimelerin bağlamını daha iyi anlayan BERT, arama motorları, çeviri araçları ve sohbet botları gibi birçok uygulamada kullanılmaktadır
T5 (2019): Google'ın 2019'da tanıttığı T5 (Text-To-Text Transfer Transformer), farklı doğal dil işleme görevlerini tek bir model altında birleştirmeyi amaçlayan bir dil modelidir. Her türlü NLP görevini metin girdisi ve metin çıktısı şeklinde ele alan T5, makine çevirisi, özetleme, soru cevaplama ve metin sınıflandırma gibi çeşitli görevlerde başarılı sonuçlar elde etmiştir.
Megatron-LM (2019): NVIDIA tarafından geliştirilen Megatron-LM (2019), milyarlarca parametreye sahip büyük dil modellerinin eğitimini mümkün kılan ve model paralellik yöntemiyle GPU kümeleri üzerinde çalışan bir çerçevedir. Dil modellemesi alanında çığır açan Megatron-LM, özellikle büyük ölçekli dil modellerinin performansını ve verimliliğini artırmak için tasarlanmıştır.
Önemli LLM Türleri ve Modelleri
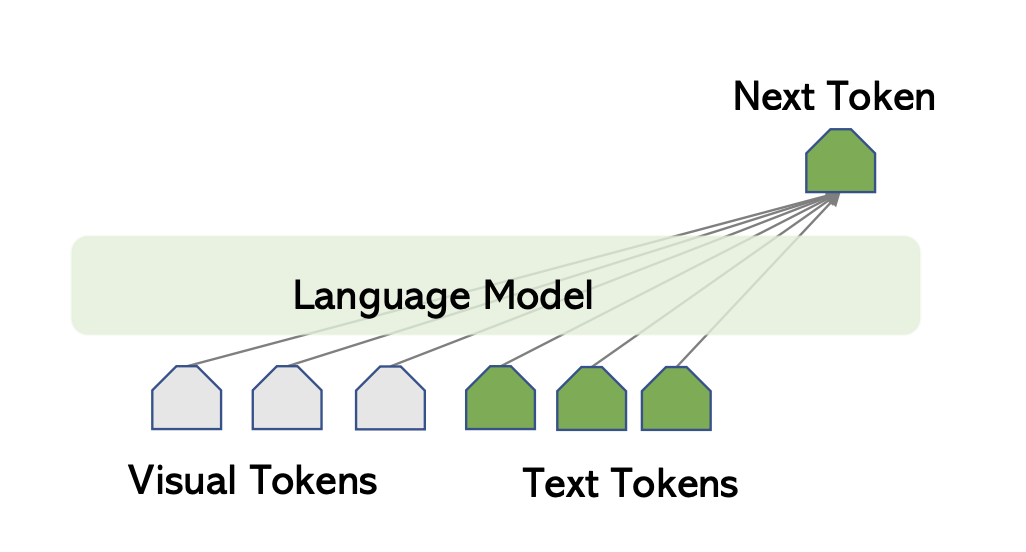
Transformer Tabanlı LLM Modelleri
GPT (Generative Pre-trained Transformer) Serisi: OpenAI tarafından geliştirilen GPT-2, GPT-3 ve GPT-4 modelleri, metin oluşturma ve dil modelleme görevlerinde öne çıkar.
BERT (Bidirectional Encoder Representations from Transformers): Google tarafından geliştirilen BERT, çift yönlü eğitim kullanarak bağlamı derinlemesine anlamada başarılıdır.
T5 (Text-To-Text Transfer Transformer): Google'ın geliştirdiği bu model, metin tabanlı çeşitli görevler için kullanılır.
XLNet: Google ve Carnegie Mellon University tarafından geliştirilen XLNet, BERT'in bazı kısıtlamalarını aşmayı hedefler.
Megatron-LM: NVIDIA tarafından geliştirilen bu model, büyük ölçekli dil modellemesi için optimize edilmiştir.
Transformer Tabanlı Olmayan Modeller
LSTM (Long Short-Term Memory): Uzun vadeli bağımlılıkları öğrenme yeteneğine sahip RNN tabanlı bir modeldir.
GRU (Gated Recurrent Unit): LSTM'lere benzer şekilde çalışır, ancak daha basit bir kapı mekanizması kullanır.
RNN (Recurrent Neural Network): Zaman içindeki veri noktalarını işlemek için kullanılan sinir ağıdır.
CNN (Convolutional Neural Network): Genellikle görüntü işleme için kullanılır, ancak bazı dil işleme görevlerinde de kullanılabilir.
Memory Networks: Büyük miktarda bilgiyi uzun süre hatırlayabilme yeteneğine sahip modellerdir.
GANs (Generative Adversarial Networks): Jeneratör ve ayırt edici olmak üzere iki sinir ağı içerir ve veri üretimi için kullanılır.




Bu habere henüz yorum yazılmamış, haydi ilk yorumu siz bırakın!...